
Nyligen uppdagades det att tiotusentals cyberangrepp genomförts mot Microsoft Exchange-servrar världen över. I den här artikeln kommer jag visa hur information om det här angreppet kan inhämtas, struktureras, bearbetas och analyseras i en plattform som heter OpenCTI.
Nyckelinsikter
- OpenCTI är en kompetent plattform för att strukturera hotinformation i cyberdomänen. Kärnan i verktyget är STIX och det är onekligen fördelaktigt om du spenderar tid på att studera detta.
- OpenCTI är kanske primärt ett verktyg för att strukturera och koppla ihop tekniska detaljer kring hotaktörer, angreppskampanjer, tekniker, verktyg, sårbarheter osv.
- STIX innebär att vi kan på ett standardiserat sätt kan beskriva hotinformation vilket öppnar många dörrar för exempelvis automatiskt och programmatiskt utbyte av information mellan olika typer av system.
Introduktion
Alright. Jag har inte skrivit många artiklar som är praktiskt orienterade och detta är således en av få. Syftet med den här artikeln är att försöka illustrera hur information från öppna källor (eller stängda) kan omvandlas till kunskap genom analys i ett dedikerat system för Cyber Threat Intelligence (CTI).
Detta avser jag göra med hjälp av plattformen OpenCTI och två källartiklar, en från Microsoft och en från Volexity. Målsättningen är att du ska se hur dessa artiklar inhämtas, bearbetas, analyseras och slutligen resulterar i en typ av slutrapport.
Jag skulle gärna inkludera fler källor och genom det fler artiklar, men då skulle jag aldrig bli klar med artikeln. Därför kommer detta arbete inte ge en komplett bild av OpenCTI och hur det används, men jag tror ändå att du kommer uppleva den tillräcklig.
OBS: Innan du läser vidare måste jag få höja ett varningens tecken. Ett fundament i användningen av OpenCTI är STIX , och det innebär både möjligheter och begränsningar. Är du inte tidigare bekant med STIX eller det ännu äldre CyBox kan kanske vissa moment kännas främmande. Det skadar med andra ord inte att läsa på lite om STIX.
Artikelns struktur
Tanken med artikeln är att den skall läsas från topp till botten och betraktas som en slags vägledning med steg-för-steg-instruktioner för hur information kan inhämtas och arbetas in i plattformen.
- Inriktningen
- Varför inhämtar vi något överhuvudtaget?
- Insamling
- Artiklarna inhämtas och sparas i plattformen.
- Bearbetning
- Upprättar rapport
- Vi läser artiklarna, extraherar diverse entiter och observerbara data.
- Analys och rapport
- Dra slutsatser, länka samman entiter, observerbara data och indikatorer.
Nog introduktion, nu kör vi igång… håll i hatten, det här kan bli rörigt.
Från information till kunskap
Steg 1 - Inriktningen
Omvärldsbevakning bör rimligen göras med ett någorlunda tydligt syfte. Dessa syften, eller behov, kan beskrivas med hjälp av en underrättelseinriktning . Vår påhittade och stående inriktning är att kartlägga de aktörer eller sådan säkerhetshotande verksamhet som kan komma att riktas mot vår organisation. Inriktningen styr omvärldsbevakningen. Vi har läst artiklarna från Microsoft och Volexity och bedömt dessa som relevant för vår verksamhet.
I det här fallet har hotande verksamhet riktats mot Microsoft Exchange, och det är en del av vår infrastruktur. Det första vi gör är att i OpenCTI skapa en Threat Report som kommer att representera den analys vi gör av händelserna beskrivna i de två källrapporterna. Threat reports skapar vi under:
Activities -> Analysis -> Reports
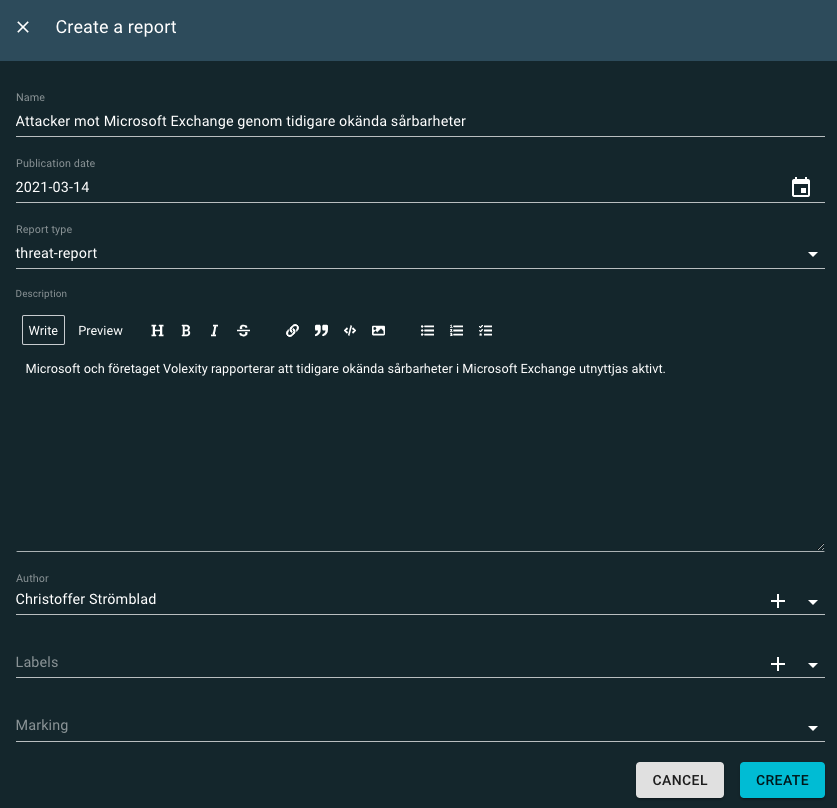
En threat report kan du tänka dig blir ett slags paraply för analysen och alla de entiter vi lägger in. Du behöver inte alltid skapa en threat-report, ibland kanske du bara vill lägga till ett nytt modus, teknik eller indikator. Men i vårt fall så förväntar sig chefen någon form av bedömning kring vad som har hänt, och vad det innebär för oss.
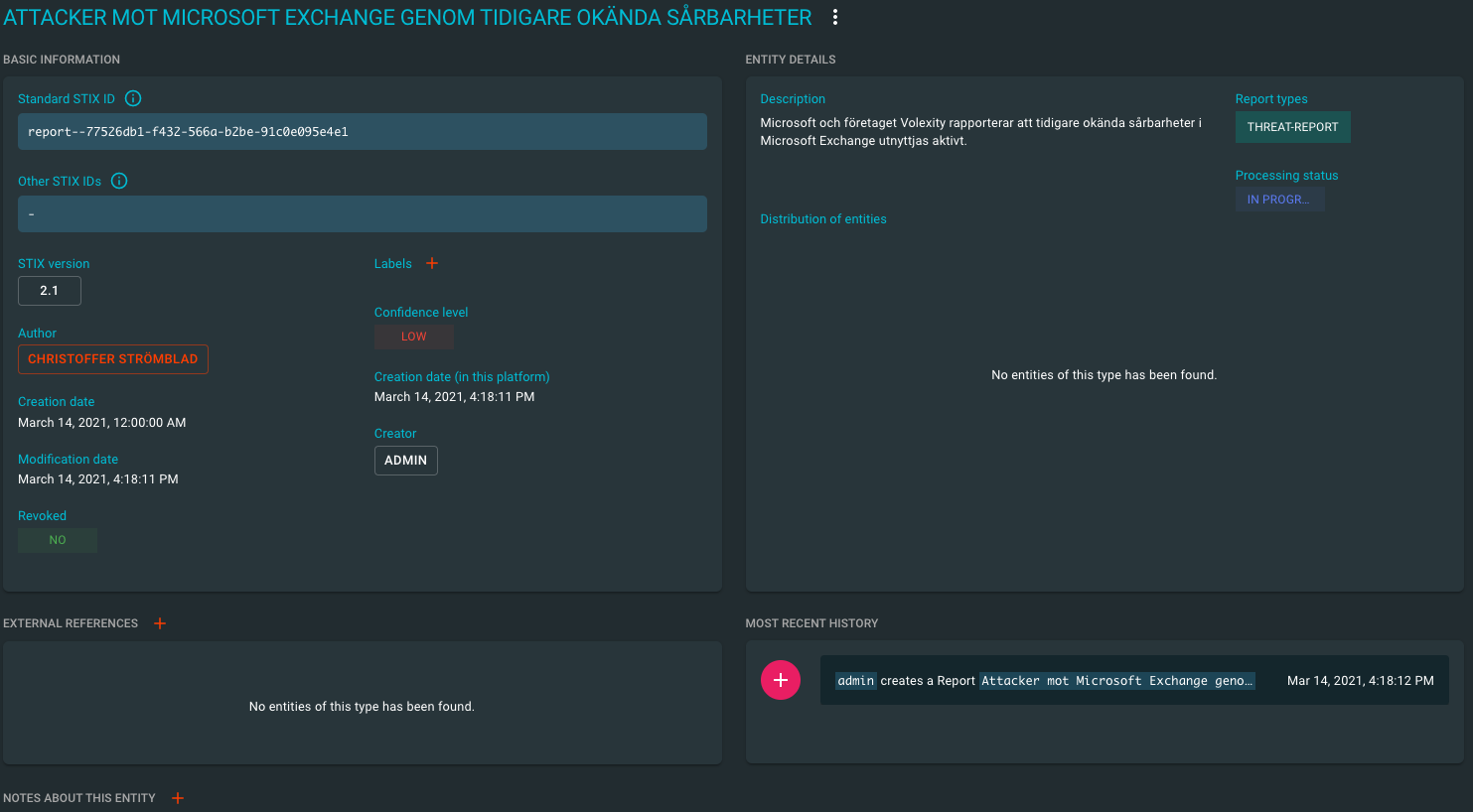
Steg 2 - Inhämtningen
Efter att vi skapat en threat report återvänder vi till våra två artiklar som vi nu ska bearbeta och analysera.
Olika källor har olika värde och med anledning av detta är det väsentligt att göra källklassificeringar. Jag skrev en artikel om hur du kan organisera inhämtning genom ett klassificeringssystem . I artikeln kallar jag kategorierna T0-T4, men har sedan ett tag tillbaka börjat använda A istället (för avstånd).
I det här fallet kommer artiklarna från vad jag benämner som A1-källor, vilket innebär att de har direkt åtkomst till information om en incident eller liknande.
Som tidigare nämnt utgår vi ifrån följande artiklar:
- https://www.microsoft.com/security/blog/2021/03/02/hafnium-targeting-exchange-servers/
- https://www.volexity.com/blog/2021/03/02/active-exploitation-of-microsoft-exchange-zero-day-vulnerabilities/
Jag väljer att i princip alltid göra om artiklar från öppna källor till PDF-versioner för att underlätta hantering och bearbetning. Och för detta använder jag verktyget printfriendly som snyggt och prydligt omformaterar artikeln, tar bort massa strunt och ger mig en trevlig PDF-version istället.
Och vi börjar med att ladda upp filerna för att säkerställa att de finns tillgängliga för framtida analyser eller om de skulle försvinna (inte särskilt ovanligt).
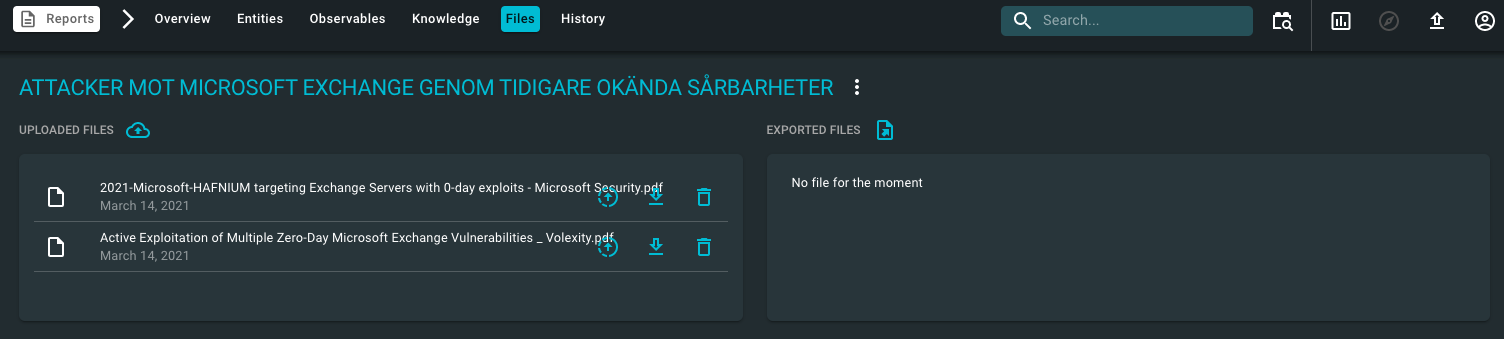
Vanligtvis sparar jag också ner rapporter, artiklar och annat material till min personliga databas som bygger på produkten DevonThink . Men det är en annan diskussion/artikel.
Steg 3 - Bearbetningen
Efter den initiala inhämtningen och behandlingen börjar det “roliga”, att läsa artiklarna och extrahera den information vi bedömer relevant. Här blir det väsentligt att förstå STIX och vilka olika domän-objekt som finns. Det är nämligen nu vi börjar tröska igenom artiklarna efter olika byggstenar som vi ska föra in i OpenCTI och då är det nödvändigt med förståelse för vilka objekt som ska extraheras.
Exakt hur man extraherar information från en artikel kanske skall betraktas som någon typ av blandning mellan konst och vetenskap. Läser du artikeln ur perspektivet OpenCTI bör du kanske initialt fokusera på olika typer av entiteter exempelvis länder, organisationer, verktyg, sårbarheter.
Steg 3.1 - Artiklarna
Så låt oss därför öppna upp Microsoft-artikeln och se vad vi kan hitta. Här är några exempel på information från artikeln vi kanske skulle välja att lyfta ut:
- “HAFNIUM primarily targets entities in the United States across a number of industry sectors, including infectious disease researchers, law firms, higher education institutions, defense contractors, policy think tanks, and NGOs.”
- Ur detta kan vi härleda Victimology: Law Firms, Defense Contractors
- Dessa placeras under Intrusion Set HAFNIUM
- “HAFNIUM has previously compromised victims by exploiting vulnerabilities in internet-facing servers, and has used legitimate open-source frameworks, like Covenant, for command and control. Once they’ve gained access to a victim network, HAFNIUM typically exfiltrates data to file sharing sites like MEGA.”
- Attack-pattern: Exploiting vulnerabilities in internet-facing servers. (T1190)
- Tools: Covenant
- “Using Procdump to dump the LSASS process memory:”
- Tools: Procdump
- Exfiltrerar information till mega.io
Det är inte särskilt ovanligt att du läser en artikel fler än en gång. När du läser en annan artikel kanske något slår dig kring första och så börjar det om igen. Inom den socialvetenskapliga och kvalitativa forskningen gör du ofta flera rundor över en text eftersom din förståelse för textens innebörd förändras allt eftersom.
Samma sak gäller när du inhämtar från öppna källor. Men här hjälper STIX till ganska mycket. Läser du med STIX-ögon kommer du automatiskt att fokusera på de grundobjekt som finns i STIX, exempelvis tools, vulnerabilities, attack patterns osv.
Och läser vi Volexity-rapporten kan vi hämta följande:
- “Specifically, Volexity has observed POST requests targeting files found on the following web directory: /owa/auth/Current/themes/resources/”
- URL: /owa/auth/Current/themes/resources
- This RCE appears to reside within the use of the Set-OabVirtualDirectory ExchangePowerShell cmdlet. Evidence of this activity can be seen in Exchange’s ECP Server logs. A snippet with the exploit removed is shown below. ;‘S:CMD=Set-OabVirtualDirectory.ExternalUrl=’<removed>’’"
- Text: S:CMD=Set-Oab…
- “Below is a summary of the different methods and tools Volexity has observed thus far: rundll32 C:\windows\system32\comsvcs.dll MiniDump lsass.dmp Dump process memory of lsass.exe to obtain credentials PsExec Windows Sysinternals tool used to execute commands on remote systems ProcDump Windows Sysinternals tool to dump process memory.”
- Tools: PsExec, ProcDump, rundll32.
Volexity-rapporten innehåller avsevärt mycket mer tekniska indikatorer vilket kanske uppskattas. Men tänk på att många tekniska indikatorer har väldigt kort livslängd, exempelvis IP-adresser. Många tekniska indikatorer bör betraktas inaktuella när en rapport publiceras eftersom aktörer då ändrar sina infrastrukturer, verktyg osv.
Steg 3.x - Observables/indicators
I sammanhang av OpenCTI kommer vi lägga in många identifierade objekt som Observables. Skillnaden mellan en Indicator och Observable skulle vi kunna diskutera en stund. Min nuvarande förståelse är att en Indicator måste innehålla de tekniska detaljerna för att programmatiskt/maskinellt kunna upptäcka en sådan. En Observable är “bara” något som skulle kunna … observeras, men behöver inte i OpenCTI innehålla något särskilt mönster (t.ex. YARA, Snort eller STIX).
Men jag ska erkänna att jag inte riktigt greppat skillnaden mellan Observable och Indicator i OpenCTI. Jag misstänker att det kan vara ett historiskt arv från innan STIX 2.x när det fanns något som hette CyBox som senare blev Stix Cyber Observable, men det är inget jag vågar satsa pengar på. Hur som helst.
Steg 4 - Analys
När vi då så slutligen gjort klart bearbetningen och lagt in alla identifierade STIX-objekt är det dags försöka sig på lite analys. Och vad är det för analys vi ska göra då? All inhämtning (okej, nästan all… bortse från anteciperande inhämtning) utgår ifrån att det finns en fråga som behöver besvaras, någon form av kunskapslucka, något vi inte vet särskilt mycket om men som är väsentligt för vår verksamhet.
Om du minns inriktningen från steg 1, kartlägga hotaktörer och säkerhetshotande verksamhet, så innebär det således att vi ska försöka besvara frågan:
Innebär den nyligen identifierade säkerhetshotande verksamheten ett hot även för oss?
En sak vi skulle kunna börja med är att skapa oss en uppfattning om “läget” genom en överblicksbild, och det gör vi genom att gå till vår rapport och trycka på Knowledge. Då får vi upp en visuell representation av hur olika delar hänger ihop, efter att vi faktiskt skapat de relationer som binder dem samman.
När vi gjort det får vi bilden nedan.
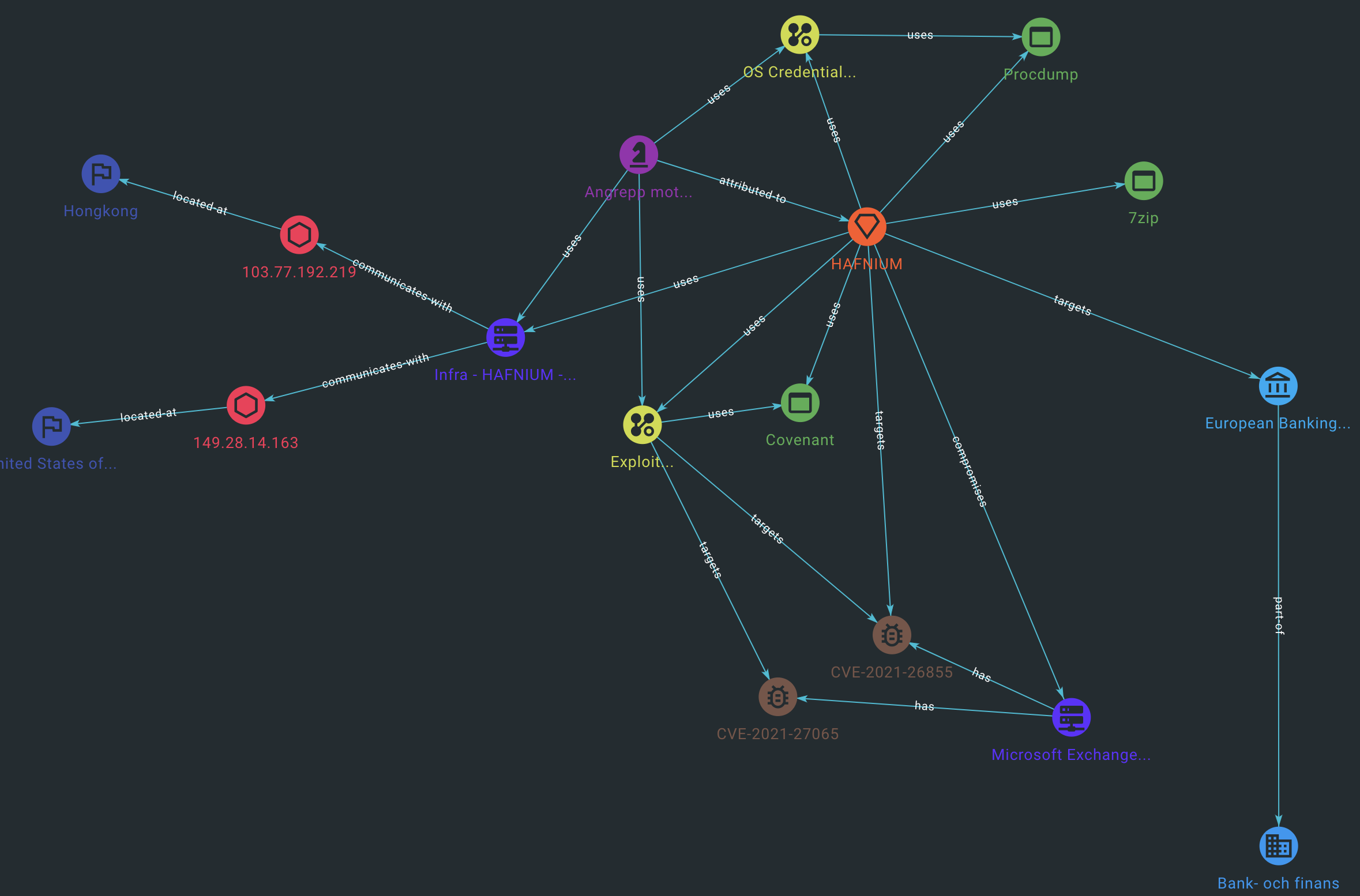
Eftersom informationen vi har lagt in från artiklarna är högst begränsad blir slutsatserna kanske inte särskilt imponerande. Låt oss börja med att besvara frågan om vilka sektorer aktören har observerats angripa. För detta så går vi till Threats -> Intrusion sets -> HAFNIUM -> Knowledge -> Victimology
Med den information som jag lagt in om HAFNIUM får vi följande:
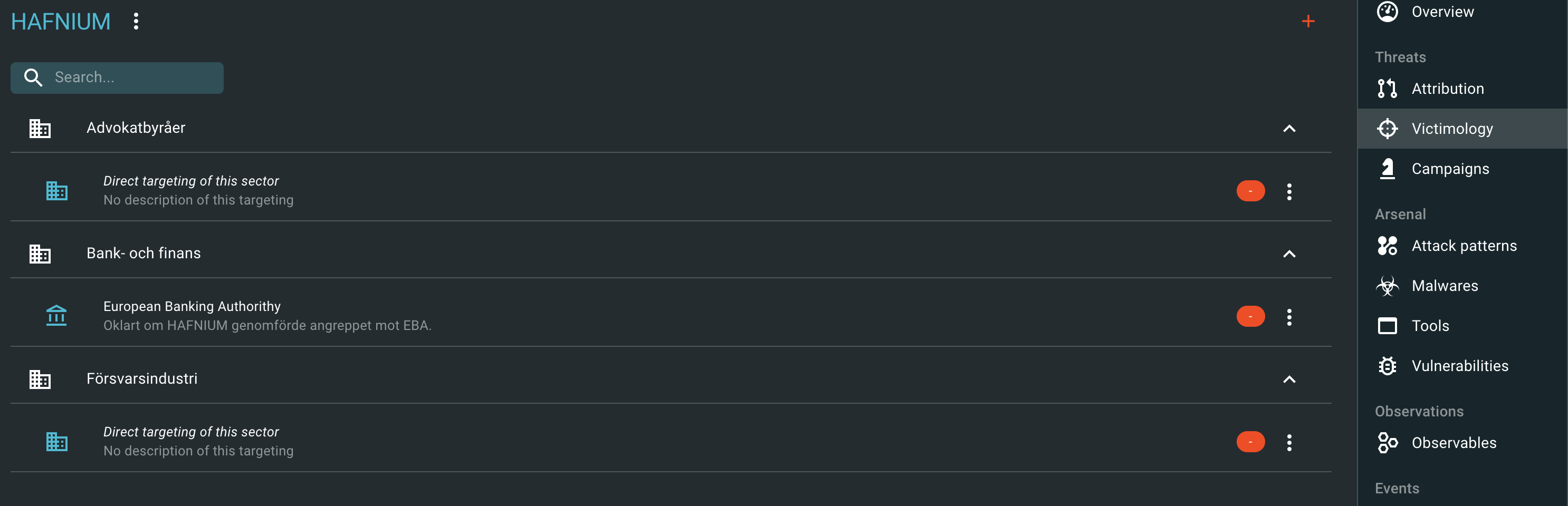
Här kan vi se att HAFNIUM har observerats angripa Försvarsindustrin, Advokatbyråer och Finans- och banksektorn. Kanske ställer du dig då frågan om vilka metoder de använder för att genomföra sina angrepp? Då går vi till Threats -> Intrusion sets -> HAFNIUM -> Attack Patterns
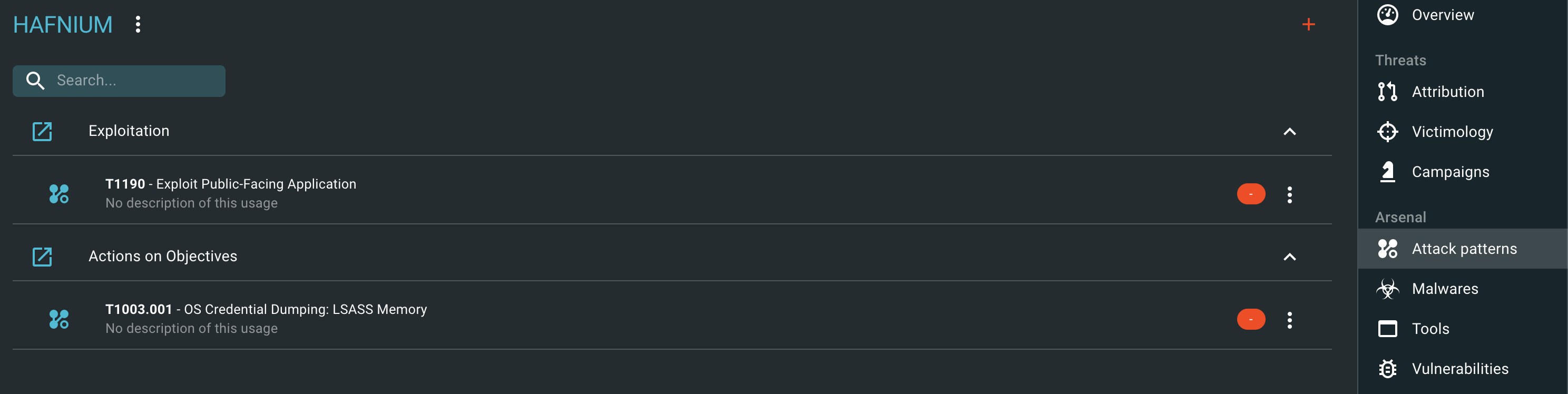
Ahh, en T1190. Har vi någon rapport om när de använt detta? Vi trycker på T1190 och får då upp följande ruta:
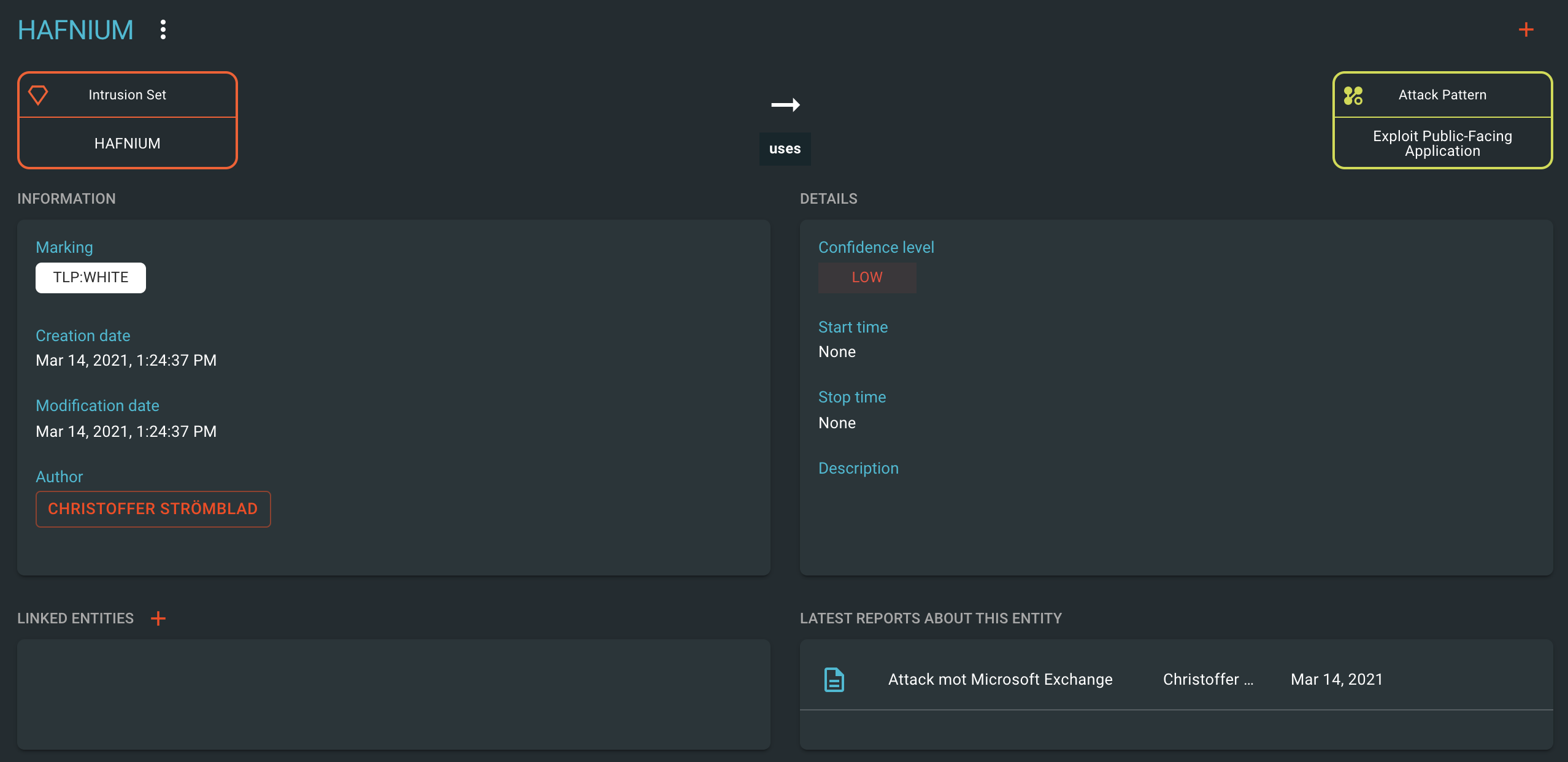
Här noterar vi att det finns en rapport minsann. Samtidigt som vi gör denna utforskning så antecknar vi och börjar sammanföra våra reflektioner och analytiska slutsatser. Antingen väljer vi att skapa en ny rapport i OpenCTI av typen Internal Report, eller så placerar vi våra slutsatser i ett annat dokument enligt någon redan etablerad mall.
Steg 5 - Avslutning
Och på den här vägen är det. Vi fortsätter att utforska de relationer vi skapat och sakta men säkert bygger vi upp en förståelse för de aktörer som vi bedömt nödvändiga att ha kunskap om. Det är viktigt att poängtera att vi behöver vara selektiva. Allting ska inte in i vårt system och hur vi drar dessa gränser är inget som enkelt kan generaliseras. Det handlar om att informationen på något sätt ska ha koppling till något som berör oss. Att bara trycka in allting vi kan få händerna på gör att vi istället riskerar drunkna i data och information som inte är relevanta för vår verksamhet eller kunder.
Att länka samman allting tar självklart en hel del tid, och dessvärre (tror jag) så kan inte skapade relationer återanvändas. Om jag exempelvis länkar samman HAFNIUM med en infrastruktur och sedan skapar en ny rapport kommer denna relation att finnas, men inte i den visuella representationen; jag tror detta är en bugg.
En av de största utmaningarna med underrättelsearbete är att den information du har sällan är tillräckligt omfattande, detaljerad eller trovärdig. Du arbetar ständigt under osäkerhet, och det handlar i mångt och mycket om att vara OK med att dra slutsatser utifrån begränsad information. Informationen som framgår i artiklarna från Microsoft och Volexity är absolut inte tillräckligt för att dra några direkta slutsatser om huruvida aktören bakom skulle kunna utgöra ett hot mot “vår” verksamhet nu eller i framtiden. Men över tid och allteftersom vi tillför ny information om HAFNIUM kanske det står klart att aktören har ett intresse av vår organisation och verksamhet.
Sammanfattning
Den här artikeln har handlat om hur vi kan använda OpenCTI för att strukturera information från öppna rapporter och genom analys framställa ny kunskap. Det finns så mycket mer att säga om “hantverket” som jag känner absolut inte fått något utrymme i artikeln. Som vanligt tar jag tacksamt emot feedback på innehållet. Om du uppskattar den här typen av artiklar får du gärna säga det och hör av dig om något känns oklart.